
Keep going
우선순위 스케줄링 본문
Priority Scheduling
- 각 프로세스에 우선순위 지정 - 우선순위를 부여하는 것
- 각 Process에 우선순위가 부여되어 있으면 cpu는 가장 우선순위가 높은 프로세스를 실행하게 된다.
- 물론 우선순위 표현할 때 높은 정수를 높게 하든, 낮은 점수를 높게 하든 설정할 수 있는데 낮은 정수가 더 높은 우선순위 나타내는 것이 일반적이다.
- 선점, 비선점 둘다 가능하다.
- SJF는 우선순위 스케줄링의 일종이다.
- burst 길어지면 우선순위 낮아지고, burst 짧아지면 우선순위 높아진다.
- 우선순위 스케줄링 문제점 - Starvation(기아) 현상 일어날 수 있다.
- 우선순위가 5인 c가 없는데 B(3)인 것 먼저 실행해서 대기. 또 더 높은 우선순위 가진 process 들어와서 무한정 대기하는 현상
- 낮은 우선순위 가진 process가 실행되지 않는 문제
- 기아문제 해결하기 위한 것 → 노화 방법 (Aging)
- process 오래 기다리면 기다릴 수록 우선순위를 점점 더 높여주는 방법
- 어떤 프로세스가 cpu를 한번 받으면 물론 더 높은 우선순위 가진 process가 와서 뺏을 수 있겠지만 이렇게 되는 경우에, 너무 하나의 process가 cpu 시간 많이 쓰게 되어 사람들이 터미널 연결에서 사용하는 온라인 시스템에서는 FCFS, SJF 들이 적당하지 않다. → 개발된 방법이 round robin
Round Robin
- 돌아가면서 한번씩 하는것을 Round Robin 방식이다.
- 각 프로세스한테 cpu 시간을 쪼개서 process들한테 조그만 time quantum을 주게 되는 것
- 어떤 프로세스가 cpu를 자발적으로 내놓지 않더라도 시간이 지나면 강제로 뺏어서 다음 얘한테 cpu를 나눠주는 방식을 round robin 방식이라고 한다.
- ex) 레디큐에 n개 process, 타임 퀀텀 q
- 모든 프로세스는 cpu 타임의 1/n 만큼 받는다.
- 1/n씩 받을 때 단위가 q time 만큼 받게 된다.
- 최대 기다리는 것 (n-1)q - 이 이상을 가지지 않는다.
- time 퀀텀 지나고 나면 cpu는 인터럽트걸 게 되고 다음 프로세스로 cpu를 넘겨주게 된다.
- time 퀀텀이 아주 크다면 FCFS 방식과 똑같이 된다.
- 아주 작으면 빠르게 CPU switch 되긴 되서 좋긴한데 context switch 많이 일어난다. (문맥 교환하는데 걸리는 시간 많이 걸림. 오버헤드가 커지게 된다.)
- 온라인 상황에서는 turn around 중요한 것이 아니라 얼마나 반응이 빨리 나오냐가 중요하기 때문에 RR 방식은 오라인 방식에 적합한 방식이다.
- 모든 작업이 끝나서 걸린 시간을 전체적으로 평균하게 되면 turn around 평균은 SJF 보다 크게 되고 response보다 작아진다.


퀀텀 적게 할 수록 → context switch 횟수↑, 낭비하는 시간↑
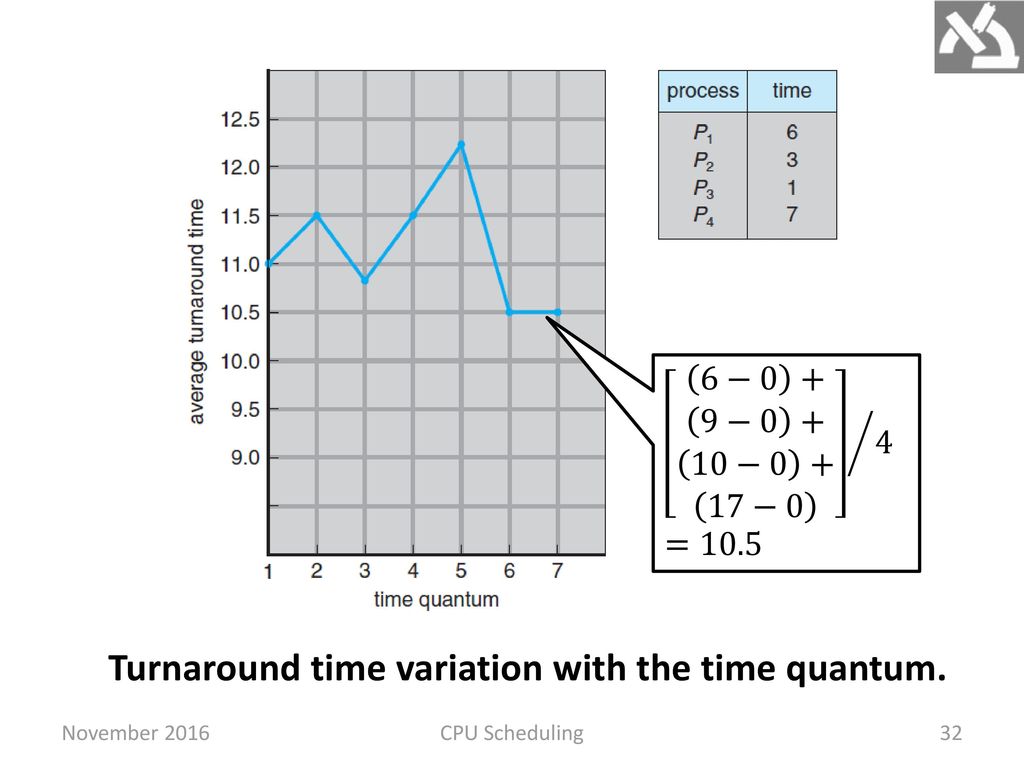
80%의 cpu burst가 time quantum 보다 더 작을 경우 turn around 빨라진다.
Multilevel Queue
- 우리가 레디큐를 여러개를 둬서 R1은 foreground 작업, R2는 background job을 집어 넣는 방식을 다단계 큐 방식
- foreground - interactive 한 작업 (응답시간 중요함) - Round Robin 방식
- background - background 작업 (turn around 중요함) - FSFJ, SJF
- 큐를 여러개를 두고 작업을 성격에 맞게 큐에 집어넣고 그 큐마다 각각의 스케줄링 알고리즘 돌리는 방법을 다단계 큐라고 한다.
- 큐간의 작업이 어떤것에 한 번 들어가면 옮길 수 없다. 다른 큐로 옮길 수 있으면 다단계 feedback queue
- 큐가 여러개가 있다면 큐들 사이에 스케줄링 어떻게 하나?
- FIXED priority scheduling
- ex) Foreground 작업이 더 중요하니까 R1이 비어있을 때만 R2 작업 수행 → R2에 있는 작업은 R1에 있는 작업 때문에 무한정 기다리는 기아 현상이 생길 수 있다.
- Time Slice (비율 나누는 방법)
- ex) R1 : 80, R2 : 20 - 기아현상 어느정도 해소 , 큐간의 스케줄링 알고리즘 고려해야 될 상황
- FIXED priority scheduling
MultiLevel Feedback Queue
- 레디큐를 여러개 두고 큐간의 작업이 이동할 수 있도록 허용하는 가장 일반적인 스케줄링 기법
- cpu 스케줄링에서 가장 일반적인 형태
- interactive job은 위에서 놀고 cpu 많이 쓰는 batch job 같은 경우는 떨어져서 FCFS 가게 된다.
- 너무 오래 기다렸다고 하면 승급시켜주는 aging 기법 적용
- 다단계 피드백 큐 고려사항
- 큐가 몇개인가
- 각 큐의 스케줄링 알고리즘 생각해야 함
- 언제 process를 업그레이드 시키느냐
- 언제 process를 강등시켜야 되나
- 프로세스가 새로 들어왔을 때, 어디 나갔다가 다시 돌아올 때 어디다 두는지 정책
Thread Scheduling
- 사용자 레벨 스레드는 스레드 라이브러리가 있어서 라이브러리가 스레드 스케줄링 한다.
- 커널 레벨 스레드 선택하는 것은 OS가 어떤 커널 레벨 스레드를 다음에 할 건가 선택하는 것이다.
- 사용자 레벨에 스레드를 스케줄링 할 때, process contention scope 라고 한다.
- 경쟁하는 영역이 하나의 프로세스다.
- 커널 레벨에서 스레드를 선택하는 것은 system contention scope 라고 이야기한다.
- 경쟁하는 영역이 시스템 전체이다.
Multicore Processor Scheduling - 다중처리기
- Homogeneous Processor : 프로세스가 모두 동등하다고 생각한다.
- 비대칭적 다중 처리기
- 처리기가 c1, c2, c3 있을 때 c1 만 레디큐 관리한다.
- c2, c3는 레디큐에서 작업을 가져오려면 c1에 요청해야 한다.
- 레디큐를 한놈만 건드리면 비대칭적 다중 처리
- 대칭적 다중처리기
- c1, c2, c3 모두 다 같은 권리 가지고 있다면 대칭적 다중처리기
- 일반적으로 가장 많이 사용한다.
- c1, c2, c3 다중처리기들이 공유데이터 동시접근하게 되면 공유데이터가 inconsistency 상태 빠질 수 있으므로 lock 을 이용해서 ready 큐 작업이 consistency 상태(일관적인 상태) 로 유지되도록 해야 된다.
- Processor affinity (친화성)
- 돌아가는 프로세스가 있다면 process 들이 자기가 좋아하는 cpu를 설정할 수 있다.
- soft affinity - 시스템이 프로세스 원하는 cpu를 지정해주는데 사정 안되면 보장을 못하는 경우
- hard affinity - cpu 세 개 있을 때 p1이 c1,c2 좋아한다고 하면 항상 c1, c2 한테 p1 지정하는 것
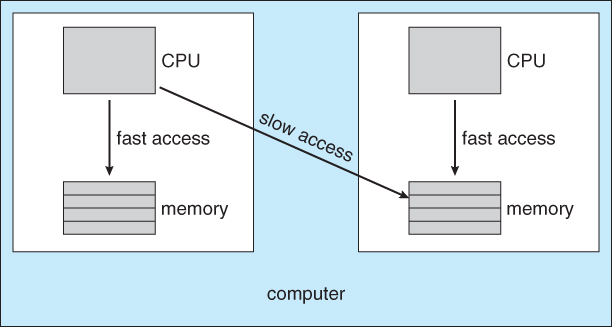
NUMA and CPU Schedulling
- c1 보다 c2가 m2 에 더 빨리 접근할 수 있다. (NUMA 현상) → PROCESS AFFINITY 발생
멀티 프로세서 스케줄링 - load balancing
- 어떤 cpu는 놀고 있고 어떤 cpu는 작업이 많이 대기하고 있는 것을 방지하기 위해 load balancing 고려
- load balancing 할려면 시스템이 부하를 주기적으로 체크를 한다.
- 강제 이동 : cpu1에 작업이 너무 많은데 cpu2 놀 고 있다면 cpu1 작업을 cpu2로 강제 이전하면 push migration
- 작업 당겨 오는 것 : cpu2가 할 작업이 없어 자발적으로 cpu1 작업 가져와서 실행한다면 pull migration
Multicore Processor
- 한 때 많이 사용했는데 점점 줄어들어 요즘은 multicore cpu를 사용하는 경우 많다.
- 하나의 cpu안에 여러개의 core를 주는 것. 메모리는 core 가 같이 공유
- 한개의 칩으로 구성 - 전력 ↓, 속도 ↑
- 1개의 core 가 있다면 여러개의 스레드 돌리는 것 일반적이다.
- 왜? core 가 메모리를 접근을 하게 되면 메모리에서 데이터를 읽어와서 레지스터에 갖고와서 연산을 하게 될텐데 cpu가 메모리를 읽어라 하고 명령 내리고 메모리에서 부터 데이터가 레지스터에 올라와서 ready 될 때 까지 시간이 걸린다. cpu는 상당히 빠른 장치고 메모리 접근시간보다 훨씬 더 빠르게 일을 할 수 있기 때문에 메모리에 있는 내용이 레지스터에 올라오는 시간동안에 core 는 놀고 있게 되는 것이다. 메모리 stall
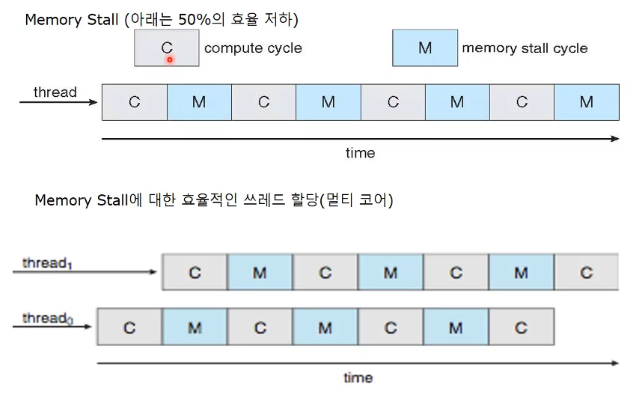
computing, memory 읽음 , computing 반복 → memory stall cycle 이 많아서 core 노는 시간 커짐
core thread 2개 돌리면, memory 읽을 때 core를 다른 스레드한테 줌
core를 thread에 스위칭하면서 실행 → memory stall cycle 동안에 core 가 일하므로 속도 훨씬 빨라짐
하나의 core에 여러개 스레드 돌리는 것 일반적
'School/운영 체제' Related Articles
more



Comments